I started my research for Openshift cloud service as part of the assignment of Cloud architectures. From the vast pool of cloud service providers we choose to evaluate five different PaaS service providers and present their evaluation or perhaps simple comparison of them. In our project plan we proposed to compare five cloud service providers on following points,
- Terms of service viz. packaging and deployment solutions offered, Automation of deployment.
- Granularity or level of customization of the provided service
- Performance offered (Service Outage and its policies)
- Data Backup facilities and how it is implemented?
- How hardware layer is implemented?
- Access control and data security concerns
- Does customer have access to ‘Access’ and ‘activity logs’?
- Billing model
- Is Maintenance and Support Service provided? If provided then, cost of the service.
- Inter operability and migration solution and it’s scope
This list seems pretty exhaustive and could cover most of the aspect of Cloud services , we think it would be sufficient in order to get introduced to a specific cloud service which happen to be the aim of the assignment. Apart from gathering information as in answering the question , We thought of actually using these service to build and upload a simple web application. In course of building and deploying the app we faced many issues and we had a solid experience of getting “hands-on” experience. All of its details are recorded below.
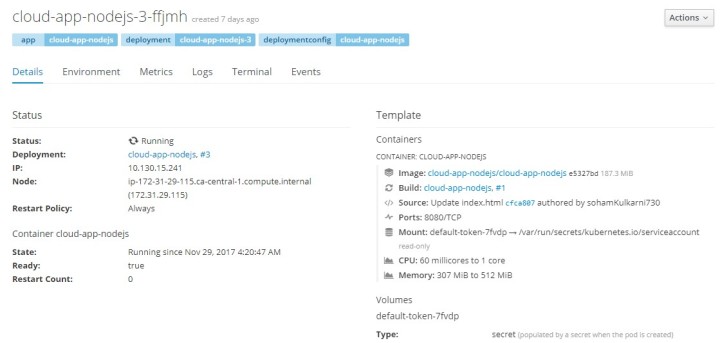
We divided work so that everyone could work independently as well as in symbiosis so that everyone could get most of the activity and maximise individual learning. I took Red Hat’s OpenShift service to evaluate. Red Hat provides it PaaS service under the hood of OpenShift . Working with openshift is easy, fast and hassle free. I ran into some problem but there are very few and non of them come out as road blocker to deployment. Unless you have very unusual platform used for your application , you could deploy and make run almost everything . Lets get into technical details of OpenShift.
Architecture :
Red hat’s Openshift has layered architecture to be used as platform for development and deployment. At its core Openshift uses Docker 1.12 and kubernetes 1.6 for development and orchestration. Docker provides linux based container images that can be deployed on a node and managed using kubernetes. Kubernetes technology is especially useful in automation of Deployment and maintaining activity . as it has automatic health checks , scaling of resource and ability of non-intrusive deployment , it really stands out amongst other cloud technologies.
little bit about Kubernetese and docker
Kubernetese : Kubernetese provides us capabilities like scaling the whole server system, , continuous , non intrusive deployment and easy monitoring over cluster.There is master node and cluster of servers containing apps. Scaling in kubernetes is really cream on the cake. it modifies the deployment by scaling the infra structure requirement automatically.
Docker : Docker uses container technology. Containers are very compact and useful as they save lot of resources. It basically composed of server, operating system , tool from Linux kernel like c- groups ,name spaces and ch-root . Thus app developer doesn’t require the whole operating system and hypervisor to run and support an application. Though ,Docker doesn’t provide container service itself but it interacts with Linux operating system to get all the basic requirement, mentioned above, to run an app.
Following is the architecture of Openshift given by Red Hat :
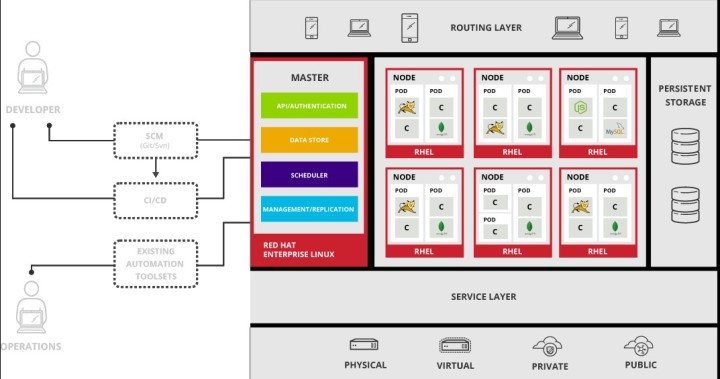
As Openshift uses Kubernetes, we can see it has one master node to control / manage cluster of nodes. Master has following components Kubernetes API server, etcd, controller manager server, HA proxy. etcd is the ideal state of requirements(infrastructure) that is store for other components to refer. While HA proxy is available to balance the load between API master which helps in recovering the system in case of failure in master node .
Controller:
Openshift has controller based architecture. Various operations has a separate designated controller which takes care of its business logic. Such architecture is useful and efficient as it opens the possibility of customization. Processes related to deployment, monitoring and scaling can be customize with the help of controllers.
Node has every resource to run a pon on it. Node runs on container provided by docker services which has c-groups, namespace and ch- root tools from red hats enterprise linux. Health of node is monitored by master and resources are adjusted accordingly.
Image registry:
OpenShift provides a image registry which can be integrated directly to container. This gives on the fly capabilities to change application Image. Image registry from third party can also be integrated with container, but has reduce functionalities.
Security:
User like developer and administrator has to put user credentials in order to access the service. All external authentication are handled using OAuth Tokens. Internal servers/ nodes uses client certificate generated by system to communicate and authenticated to perform an operation.
Authorization is managed by policy engine which remembers the user rights. Policy engine remembers rights like creation of pod, changing service, Changing Pod description, deployment, application image change and groups them according to role in policy document.
Granularity or level of customization of the provided service:
As it uses controller pattern to handle micro services, user get hold of many customization opportunities. Controllers can be programmed as per user requirement and way of operations can be tweaked as per requirement. Though many of the services doesn’t require a change, it manly deployment and image registry integration that is need to be customize. User can use web console to do so or can use command line tool available on browser.
Persistent storage Data Backup facilities:
Persistance storage works on kubernetes persistence volume. It is networked storage in cluster that has been created by administrator and pods can be connected to persistence. Every user can raise request for persistent storage/ persistence volume (PV) via Persistence storage claims(PVC). All the communication with PV is handled by PersistentVolume API. PVs are not part of free service, in order to avail or claim PVs user need to pay premium fees.
As mentioned earlier, Openshift provides a way to integrate third party image repository with the containers. This is an indirect way of having image backup, this comes out to be very critical in case of failure. Though no data backup facilities were explicitly mentioned by Red Hat.
Networking :
Pod’s network requirements like IP address, bandwidth are provide by kubernetes from internal network. Assigning IP addresses from internal system ensures that all pods are within same host. There are no interconnection provided between pods, it is recommended that pods should talk to each other by developing services.
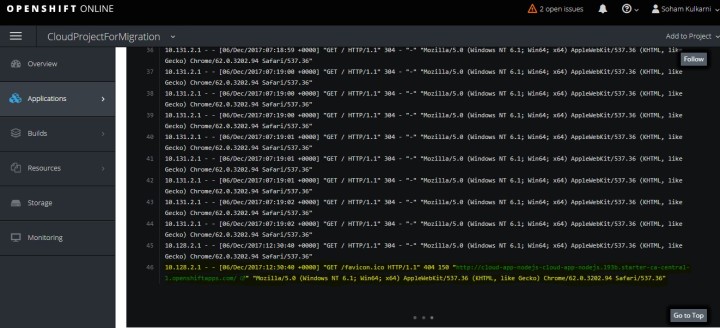
‘Access’ and ‘activity logs’ :
Activity log is very important in order to keep track of resource requirement and knowing users of your app. In Openshift, User can view activity log using online command line tool. Detailed information about request received and resource utilized is logged in command line. Below is the screenshot of activity log. And the highlighted part is the request for application.
Billing model :
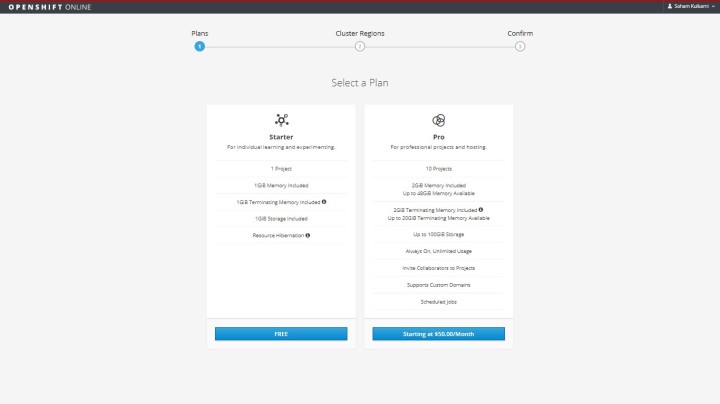
There are two plans , starter plan and pro plan.
In Starter, there is no basis charges, only one project is allowed containing maximum pods. User get 1GB of memory, 1 unit of computation power, 1 GB of persistence storage and logging capacity of 24 hours.
While in Pro plan, user is allowed to build 10 projects. 2 GB of memory Expandable memory with rate of $25/ GB/ Month , maximum pod number of 192, 4 units of CPU power , and logging capacity of 7 days.
Send my first app to cloud : Following link is very helpful and serves as one stop solution for first time deployment.: https://docs.openshift.com/online/getting_started/index.html
I followed following steps
- First step is to log to Red hat enterprise website using user credentials. Note that these credentials are very important and will be used for authorization hereafter.
- After login you will be asked to choose plan which basically means level of service.
I have chosen starter plan as it is completely free.
- Then user is asked to choose cluster . Four choices are enlisted on Openshift’s website but I received only two choices. I chose Canada as it stable than US clusters.
- It takes a while to account to be activated. Note that my account is mentioned as queued for provisioning. As account is active , user can viw the dash board where various options are displayed.
- Following is the dash board of Openshift. Openshift include 28 different technologies like ruby , python, mongoDB, node js, perl, PHP and many more.
- User can now start using this dash board for deployment. I had one Node.js application with me and I decided to deploy that application on openshift.
- Select the platform you want to use (it will be node.js in my case). Here we can see the Git repository link. Paste git repository link there. Openshift will copy all the git repository to docker image and code will be ready to deployment.
- Project will be Online and running .